I built the dashboard around a manager workflow
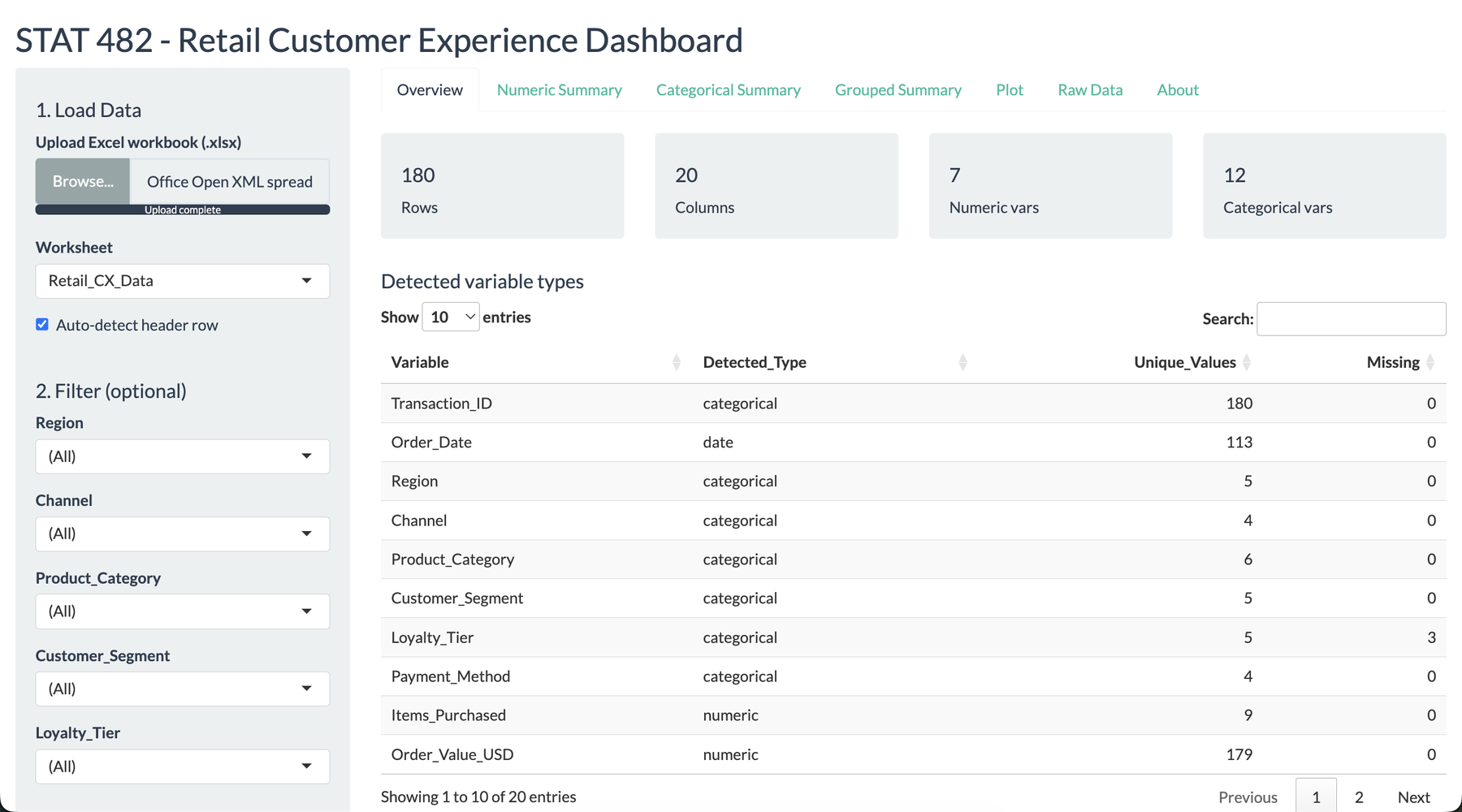
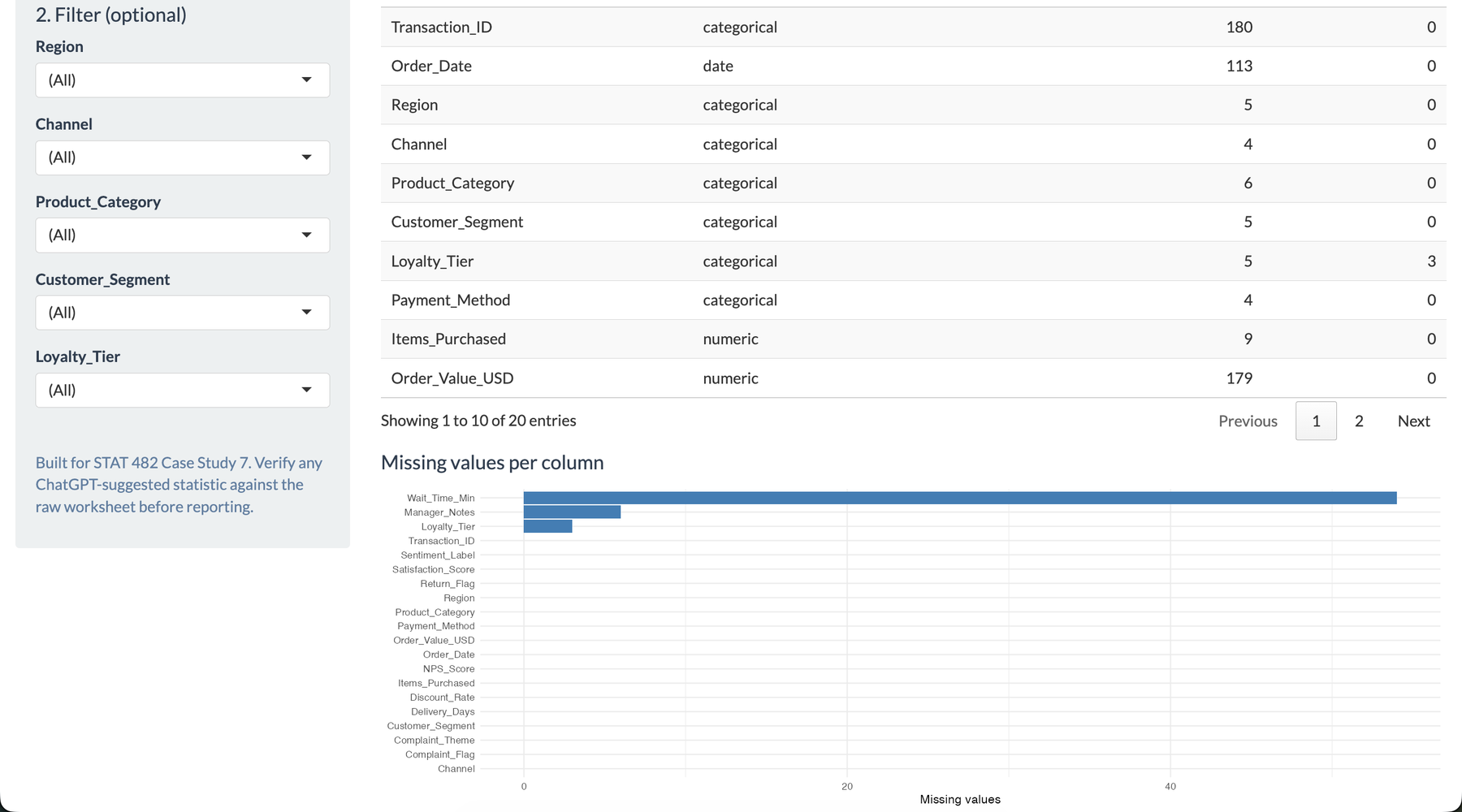
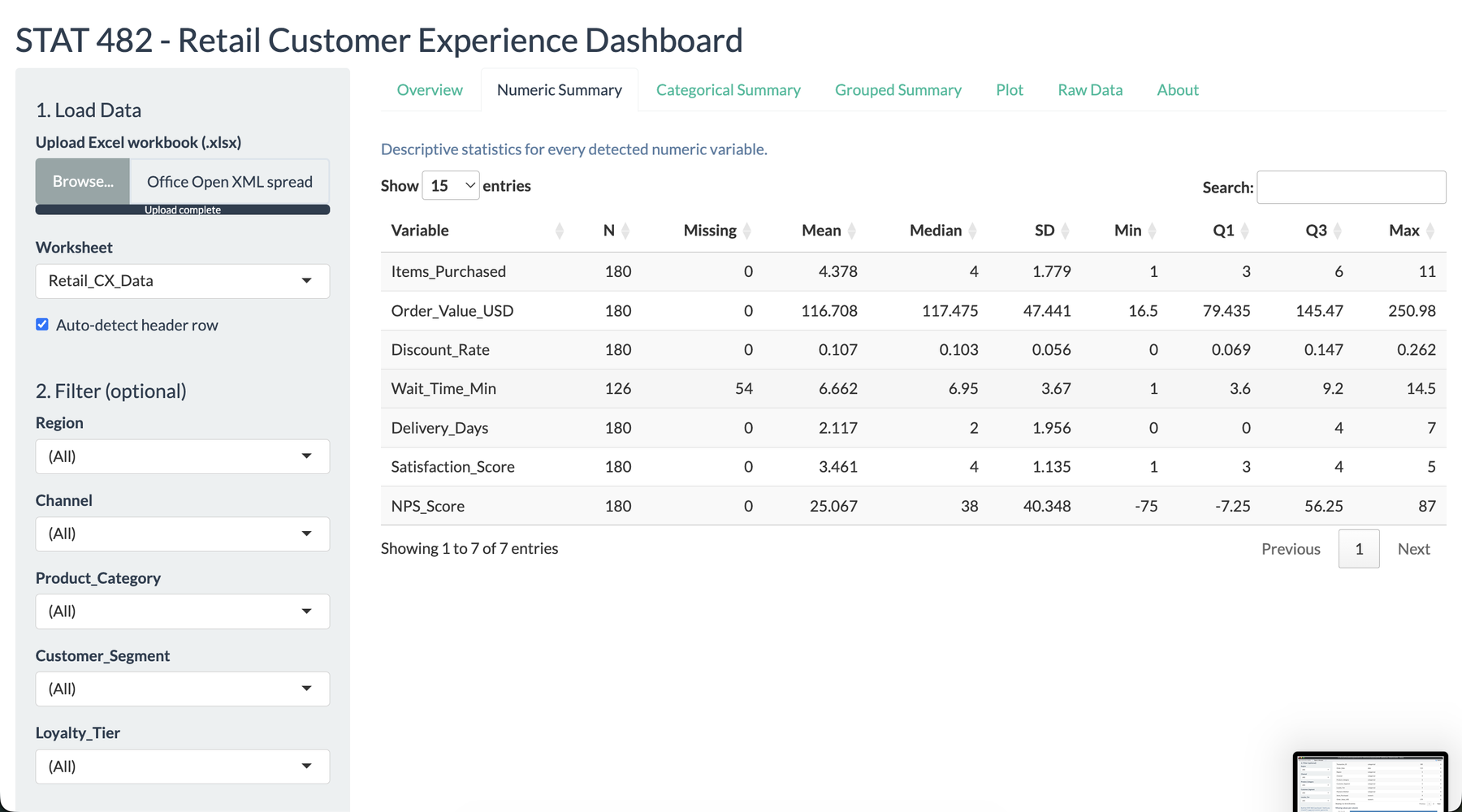
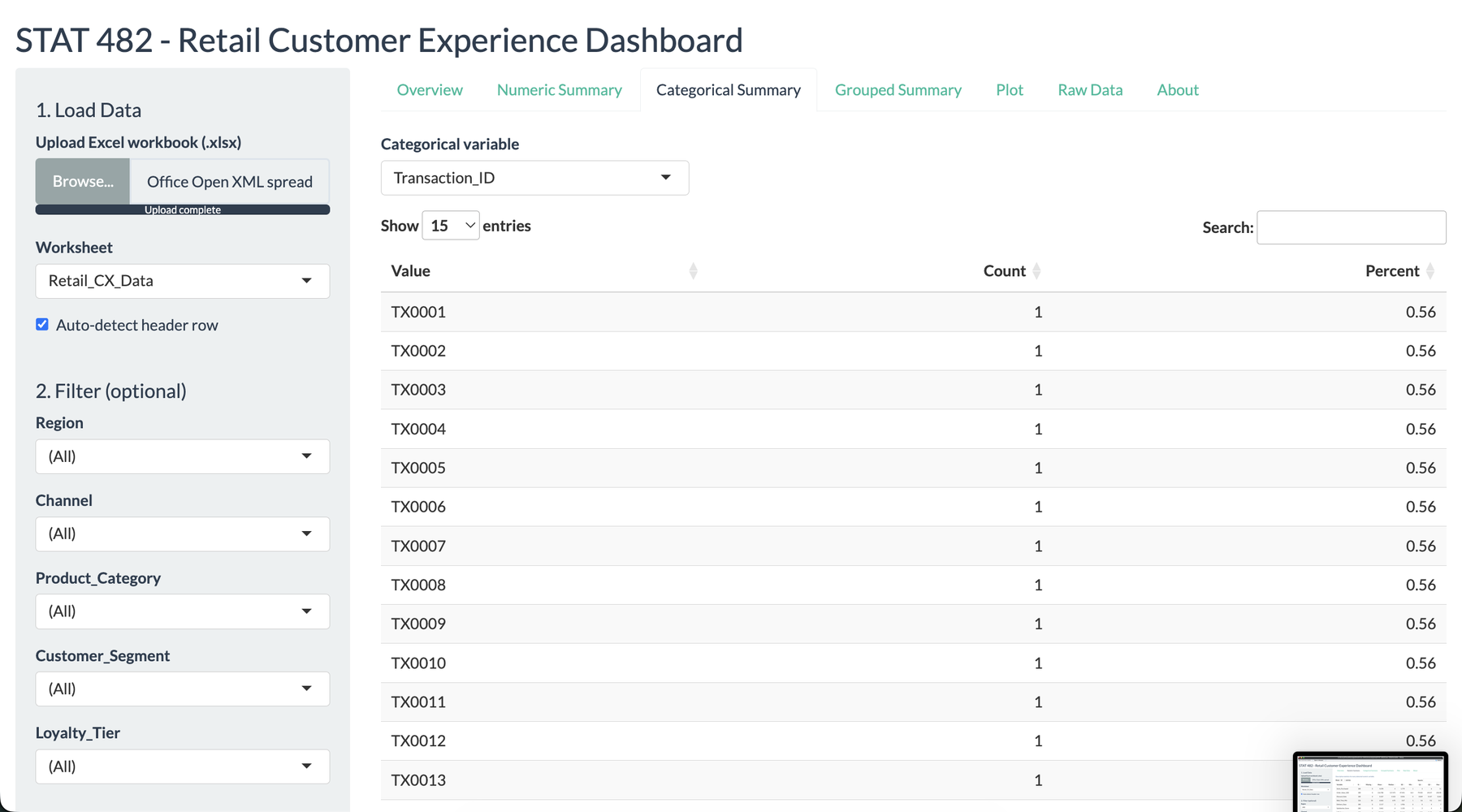
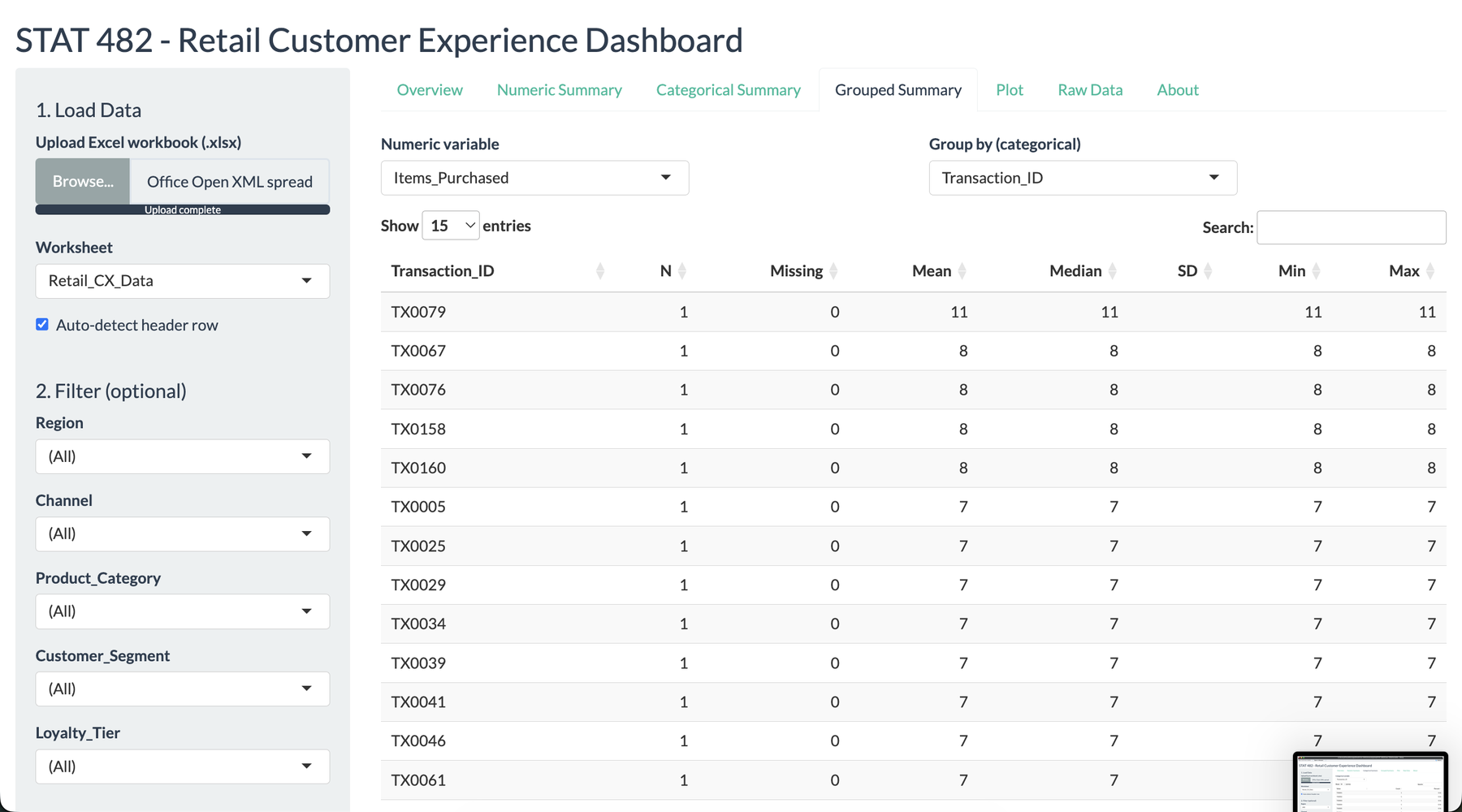
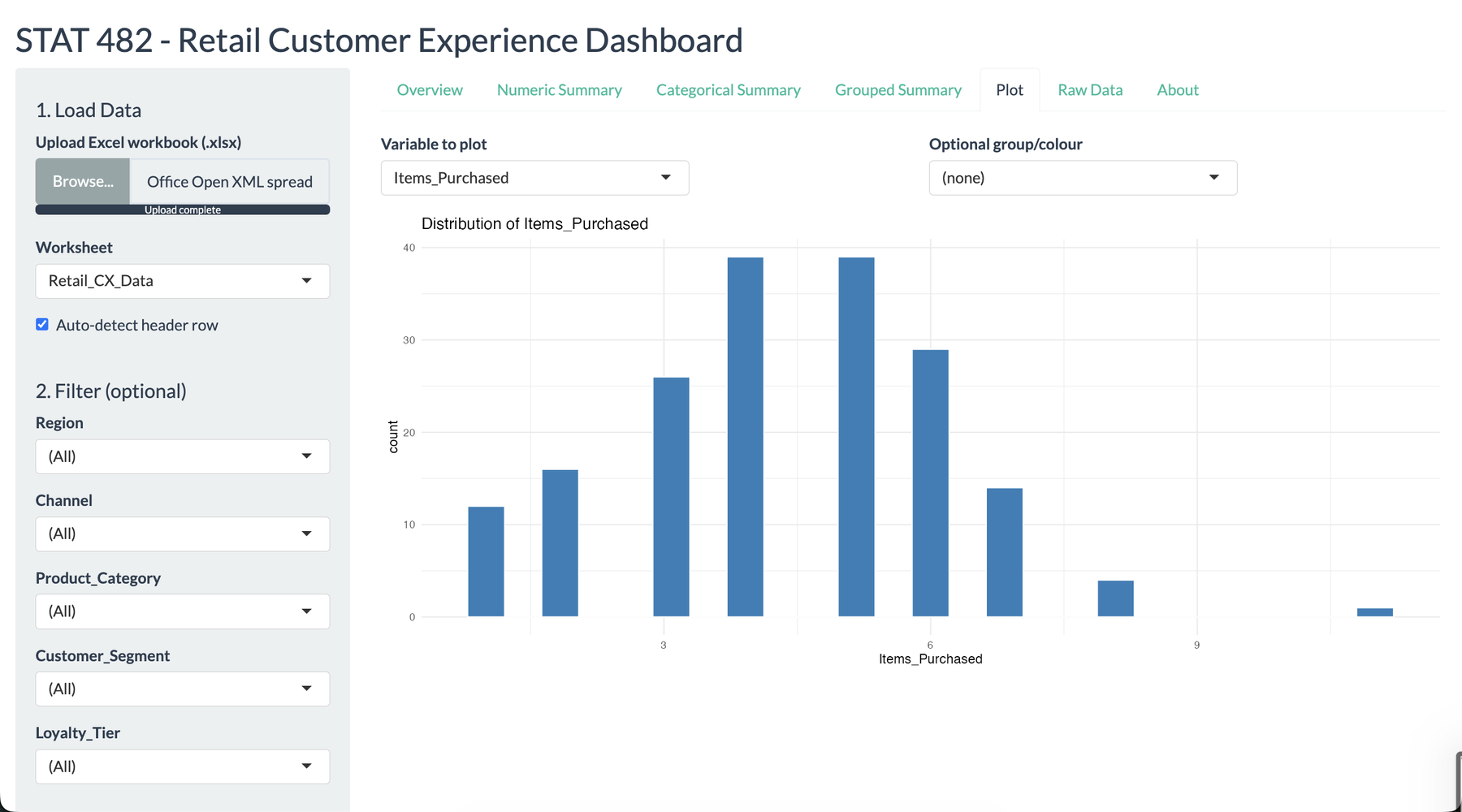
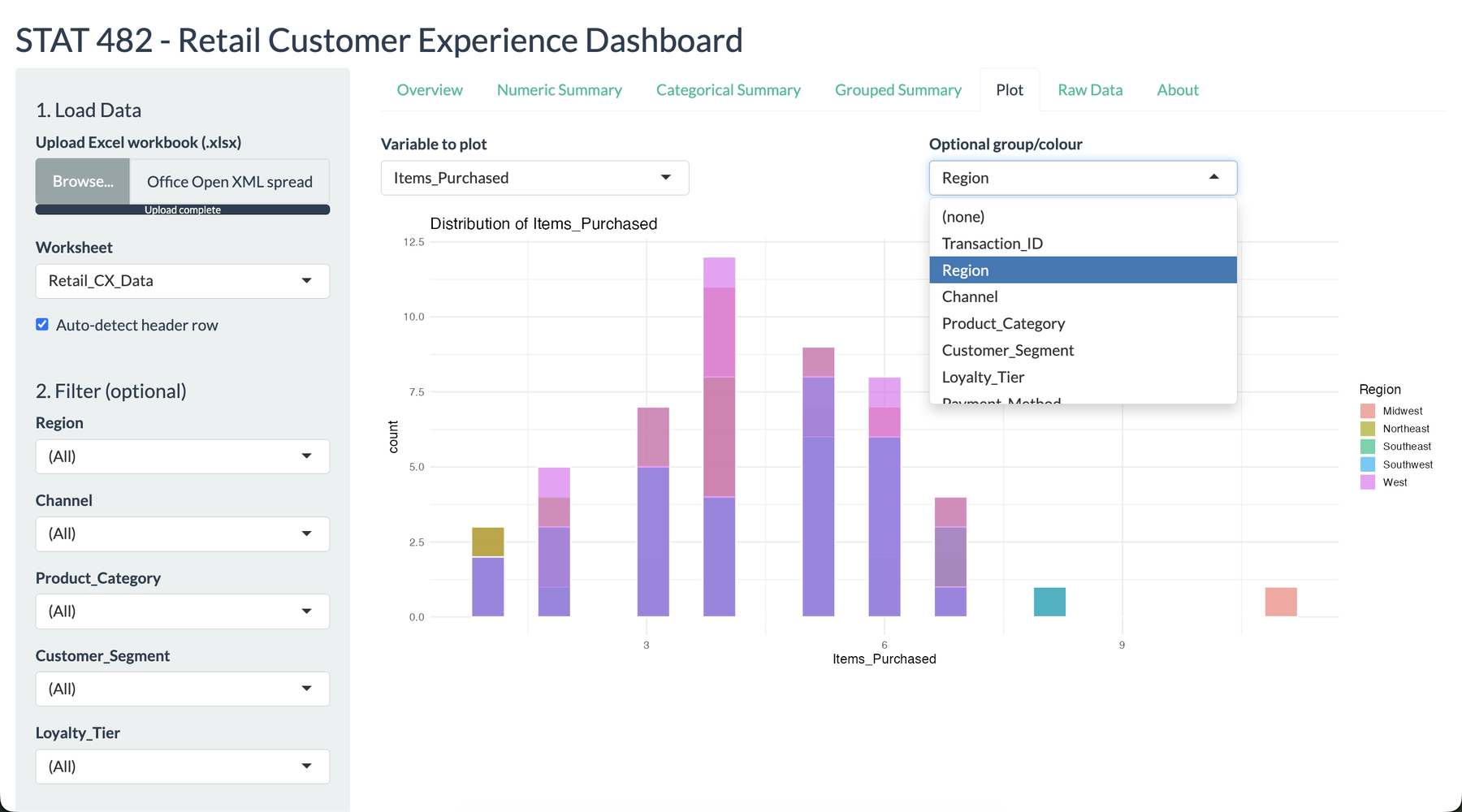
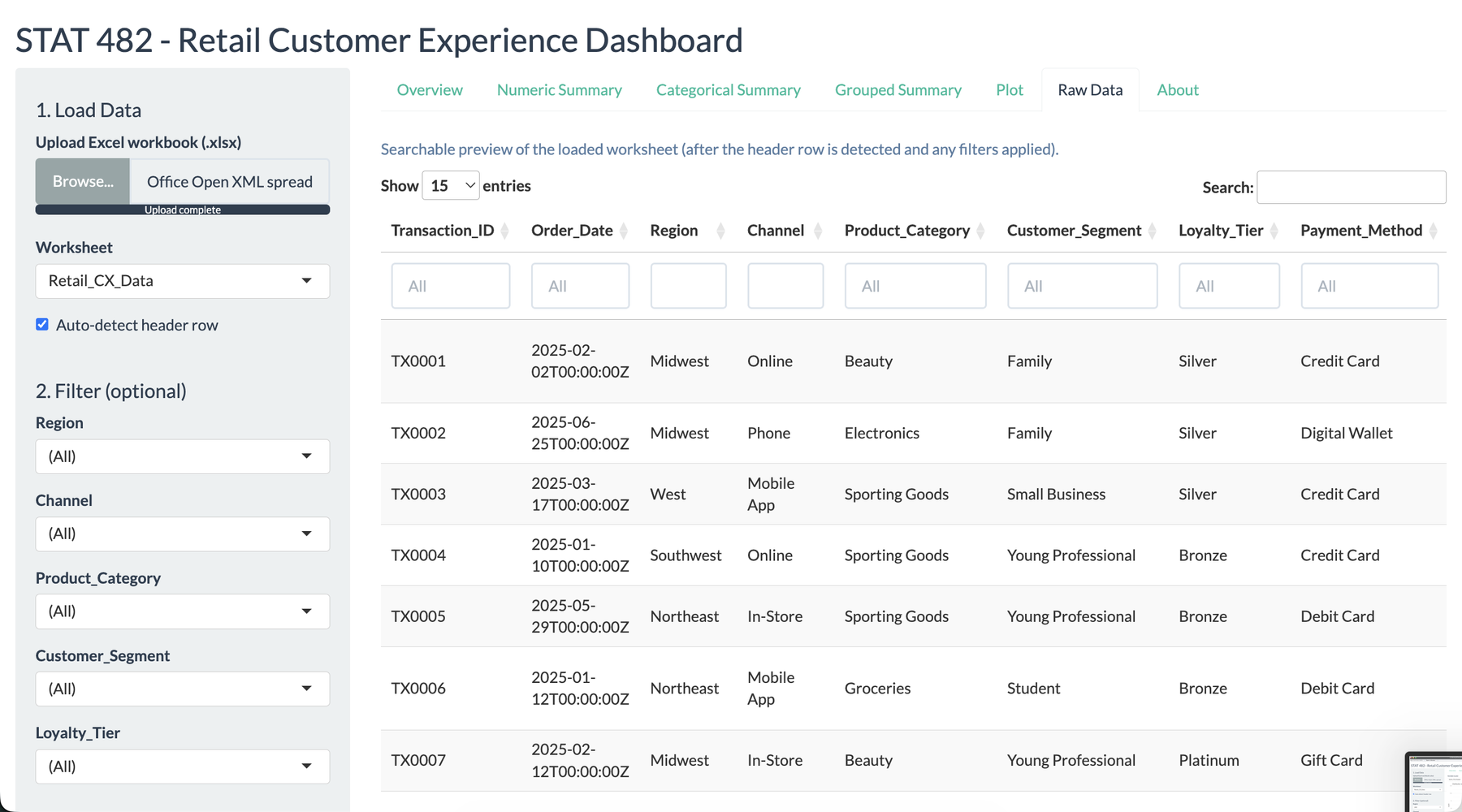
I wanted this project to feel like a tool a store manager could actually open during a review meeting. The opening screen summarizes the uploaded workbook, identifies the detected variable types, and gives immediate confidence that the data was read correctly. That mattered to me because the dashboard was not meant to impress with code first. It was meant to reduce the distance between a messy workbook and a useful decision.