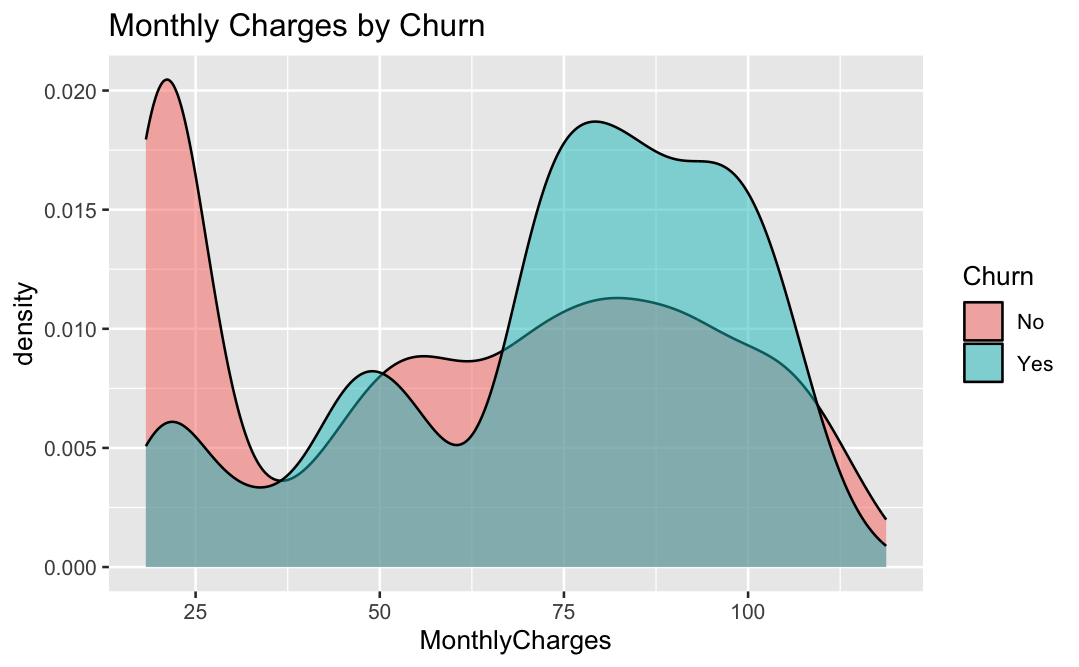
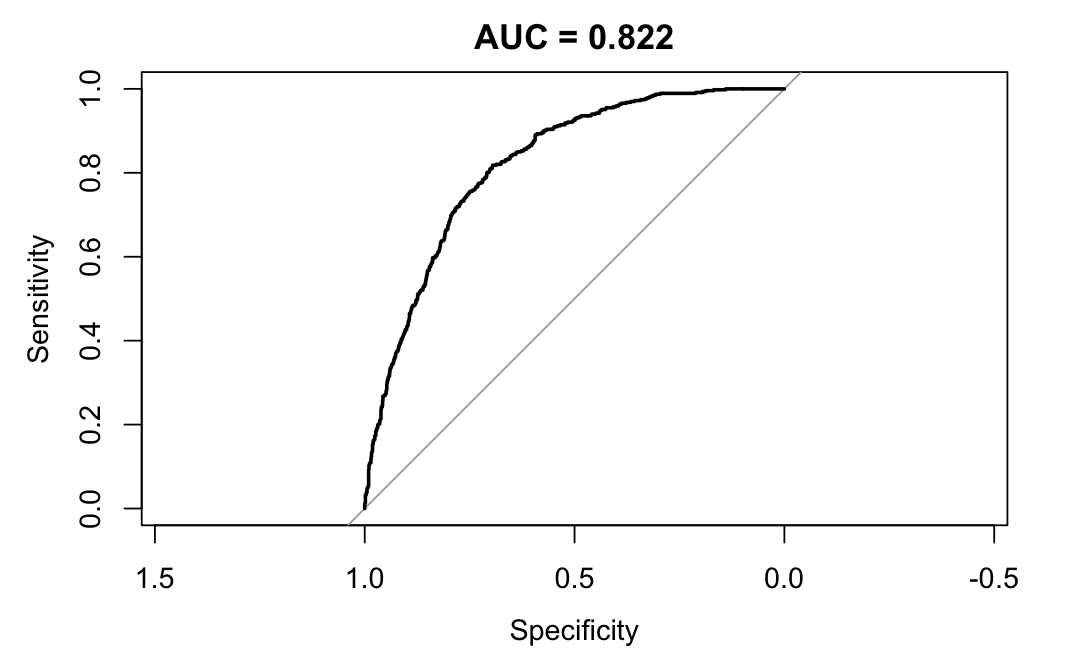
I started with the retention decision, not the algorithm
The case begins with a management problem: acquisition can look healthy while revenue stalls because existing customers quietly leave. I framed churn prediction as a resource-allocation problem for a retention team. The goal was to identify accounts worth acting on, explain why they were risky, and keep the model transparent enough that the recommendation could be defended in business language.