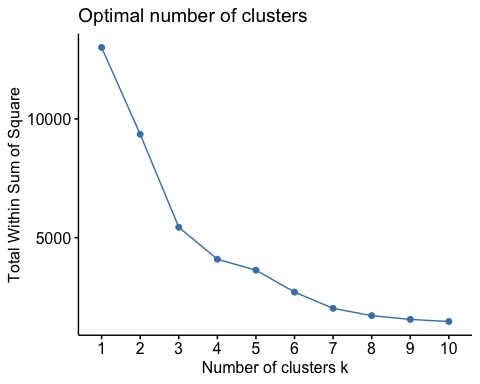
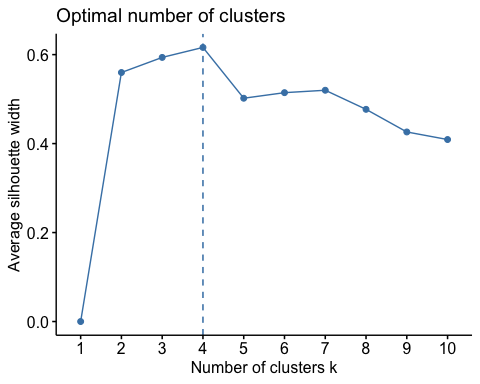
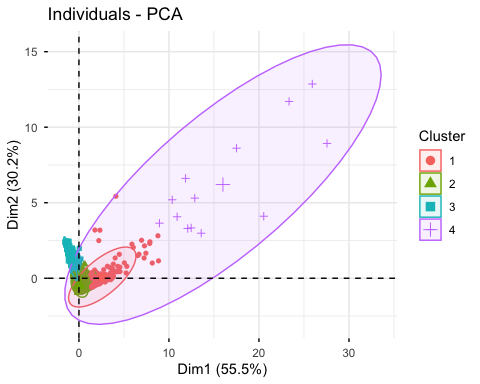
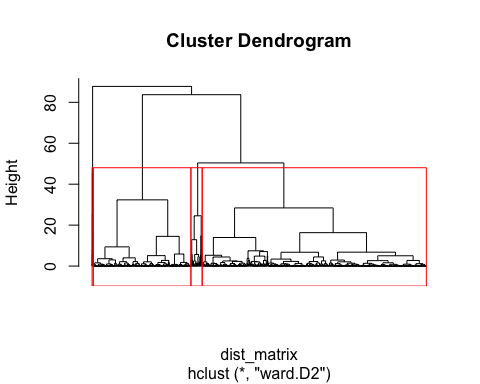
I framed segmentation as a marketing decision
I started the case from the management problem rather than the algorithm. A one-size-fits-all marketing approach wastes attention because the same offer will not mean the same thing to a VIP customer, a regular buyer, and a lapsed account. My objective was to create customer groups that were analytically defensible and easy enough for a marketing team to act on.