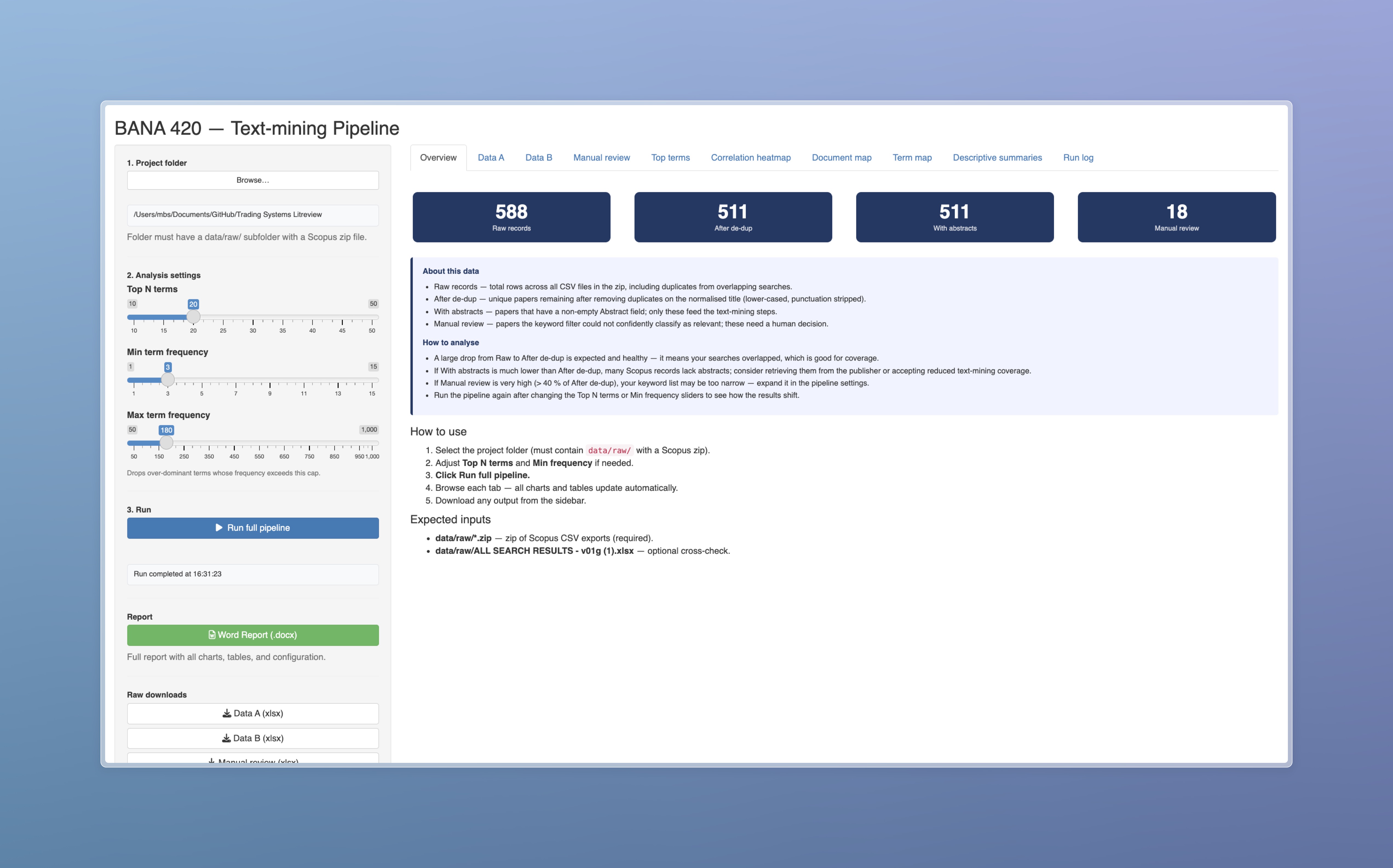
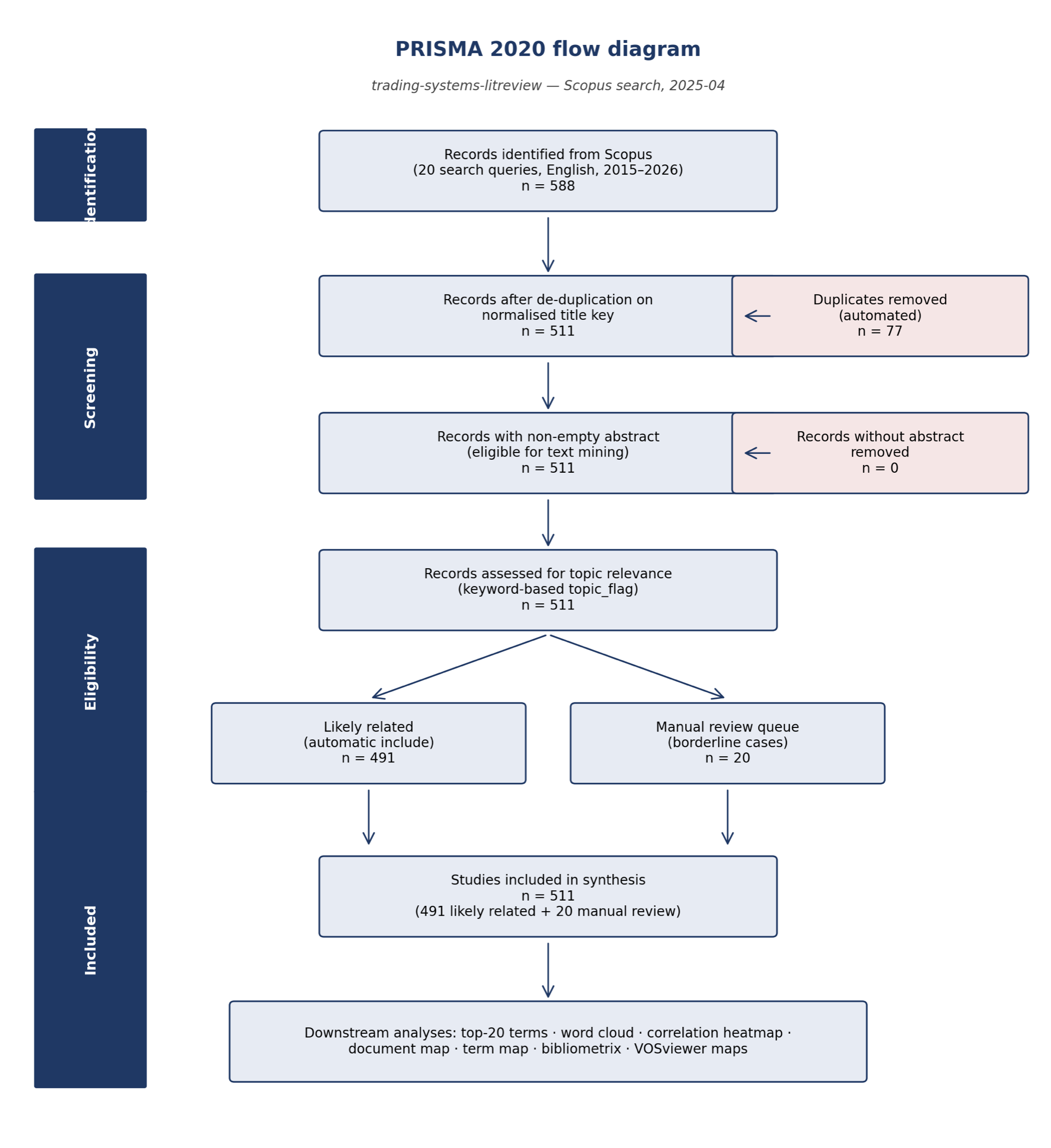
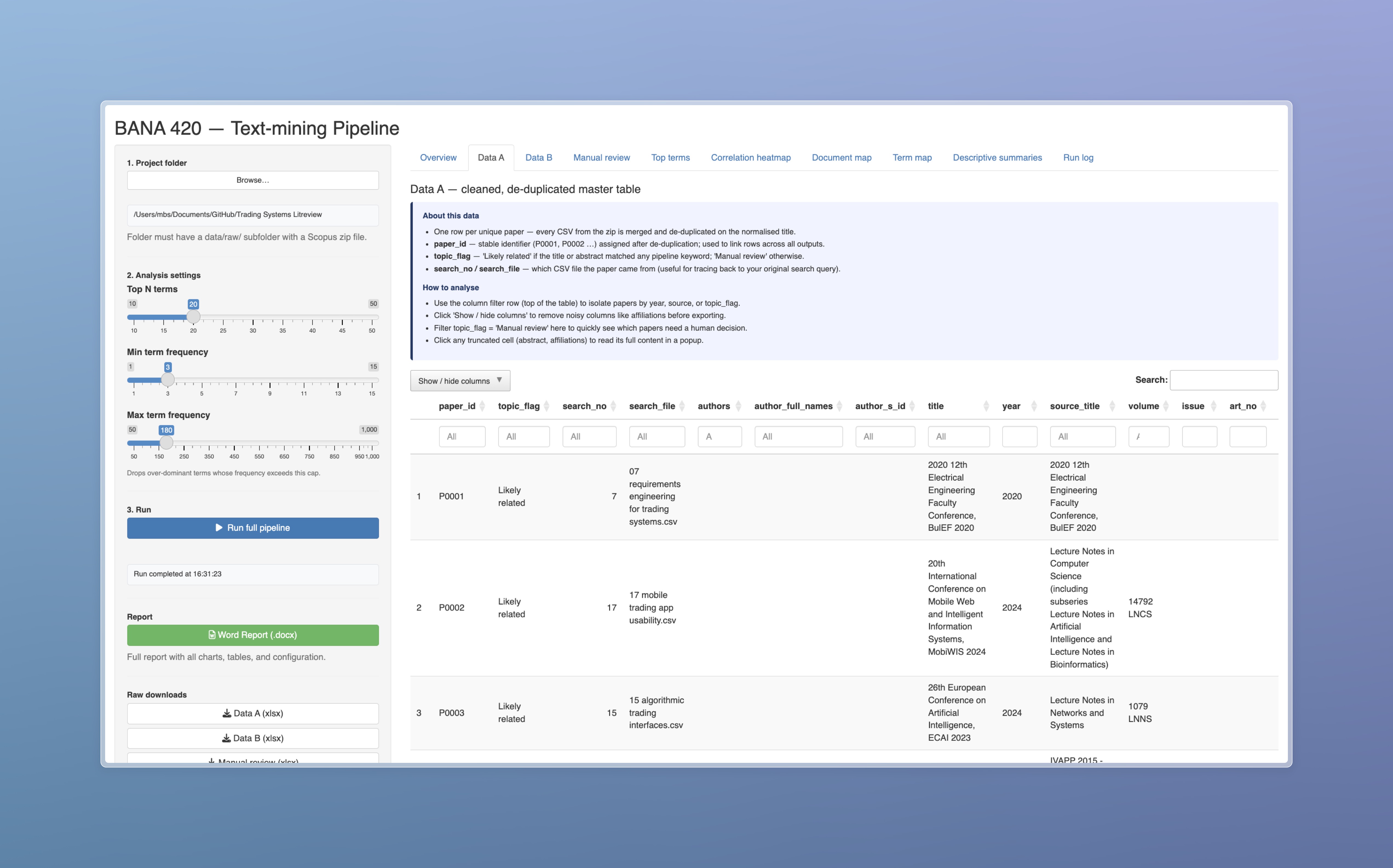
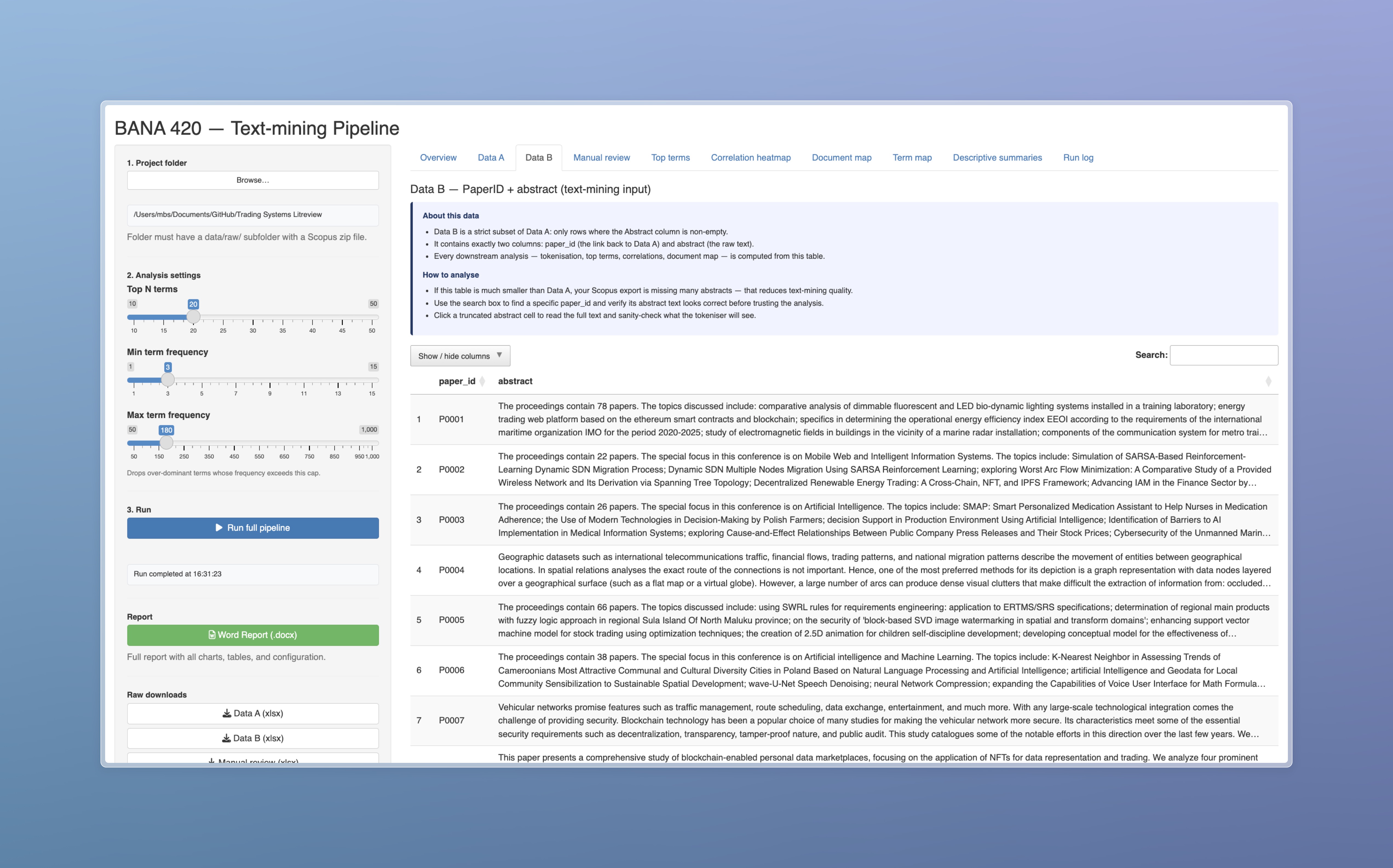
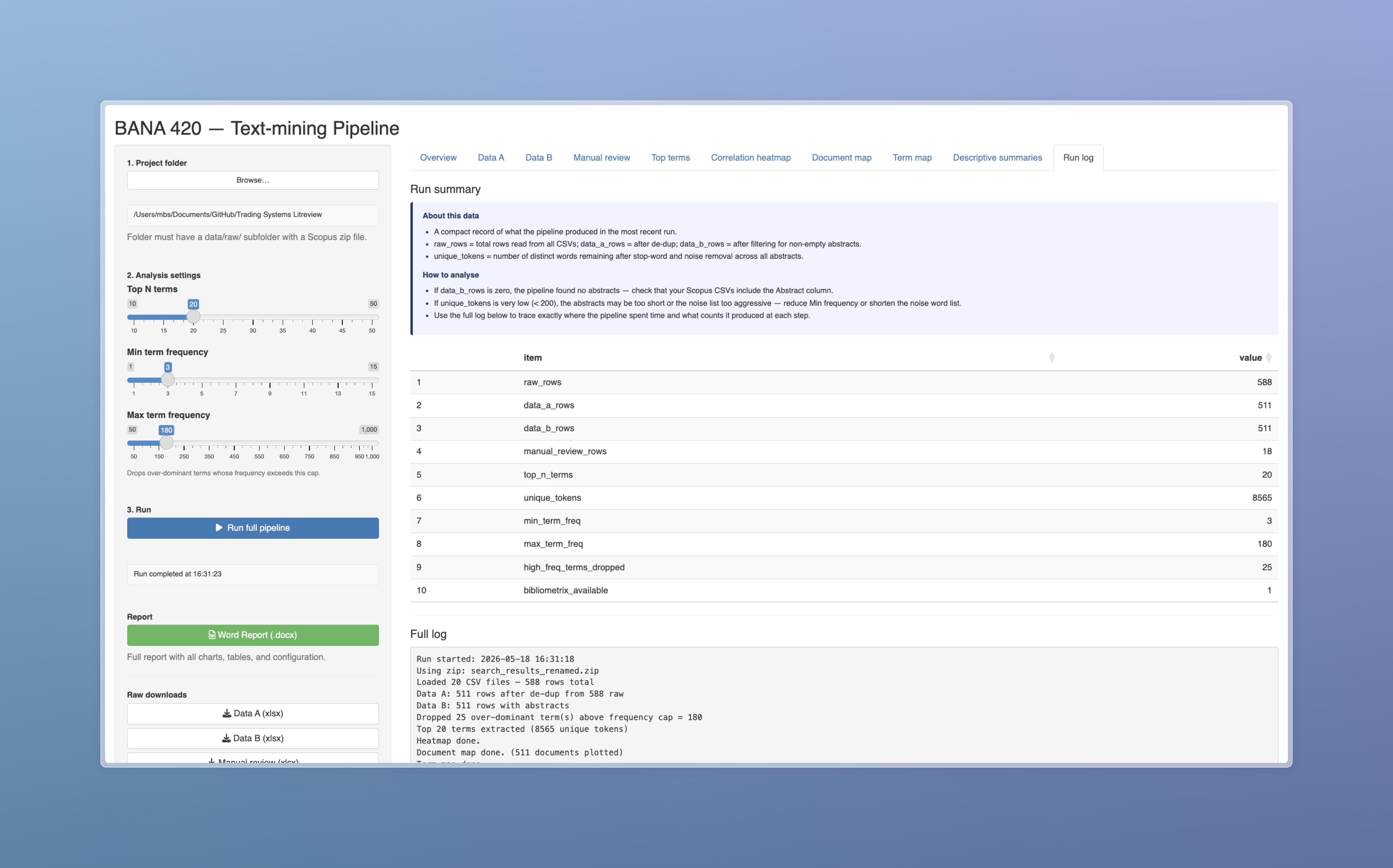
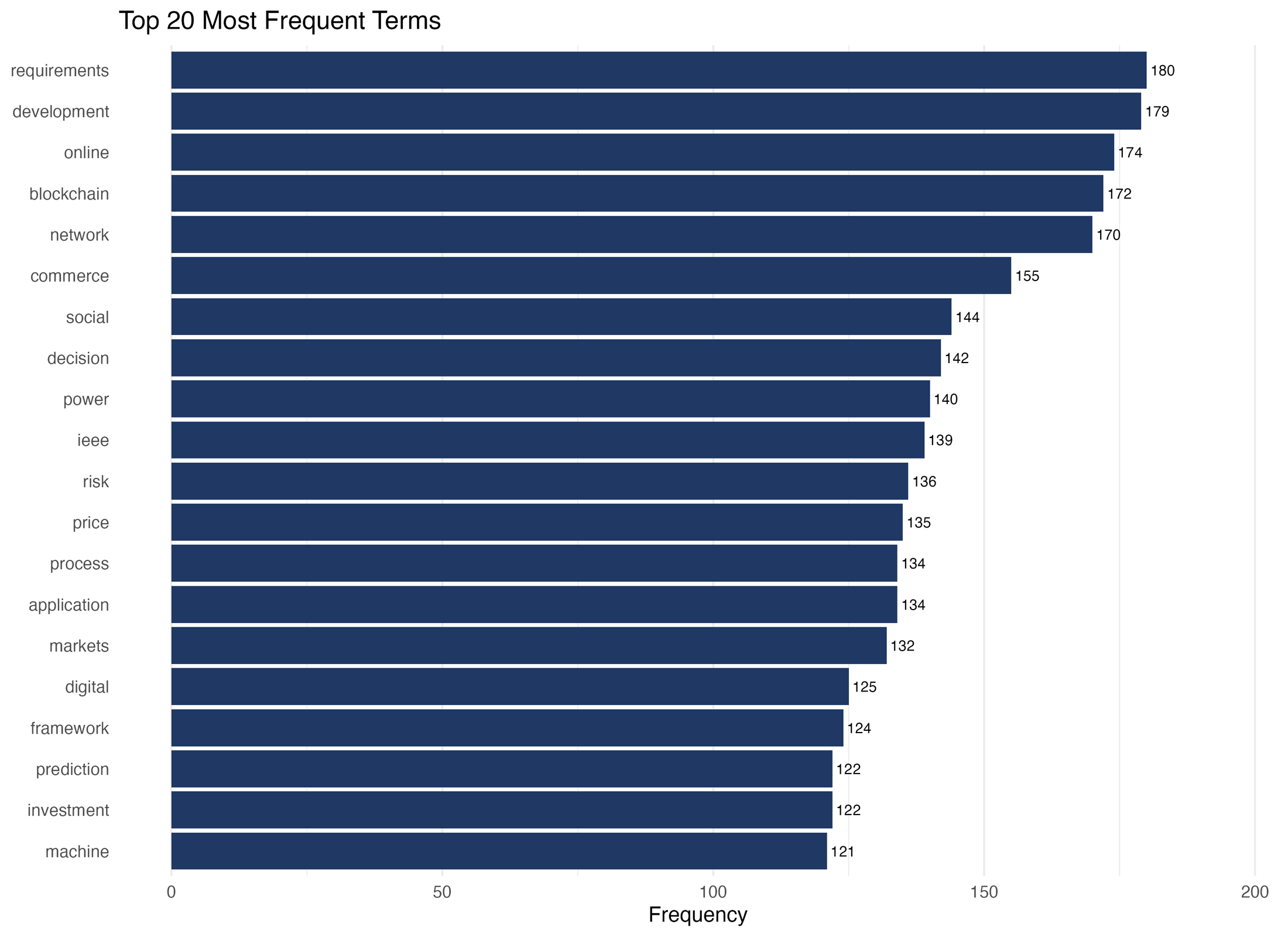
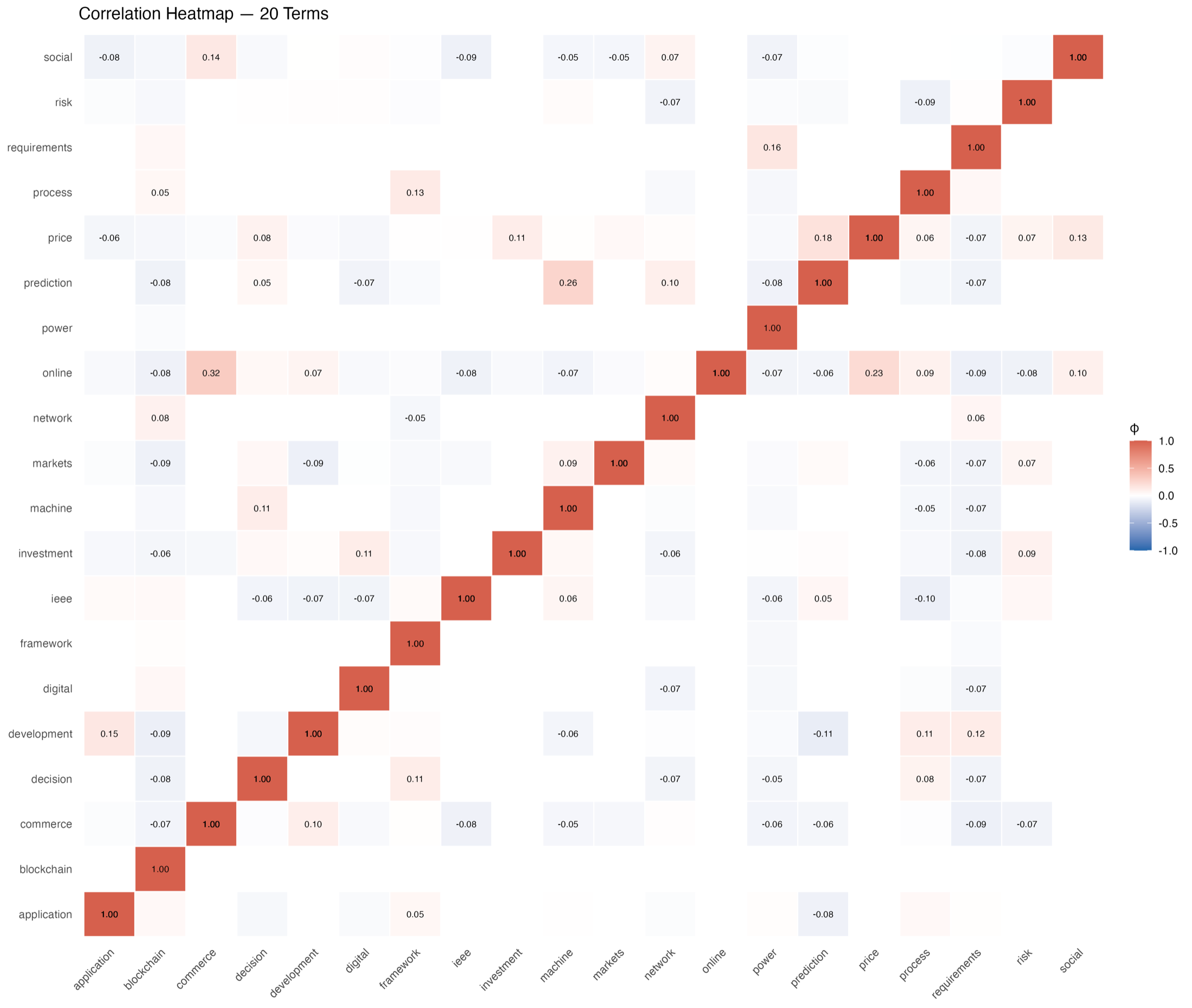
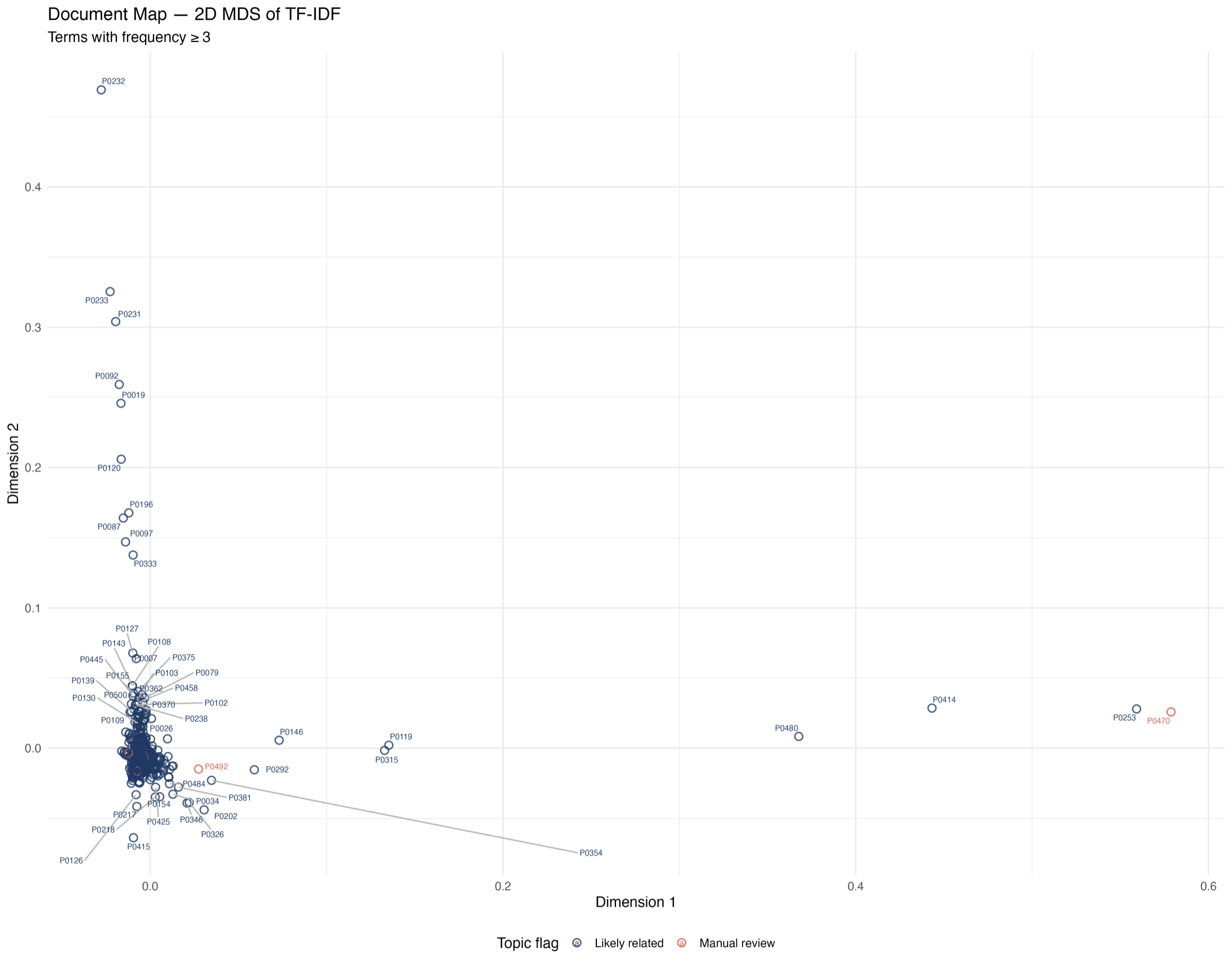
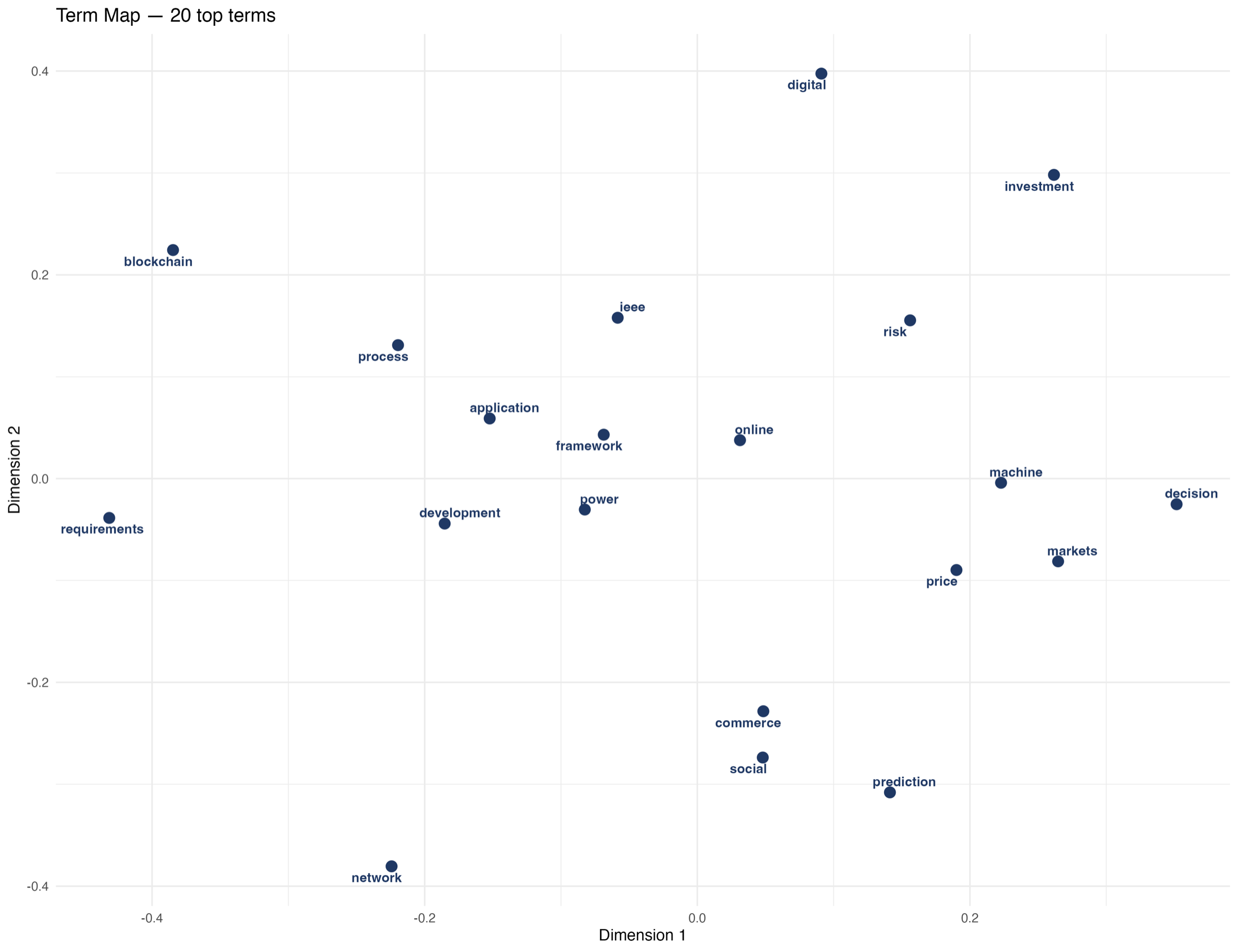
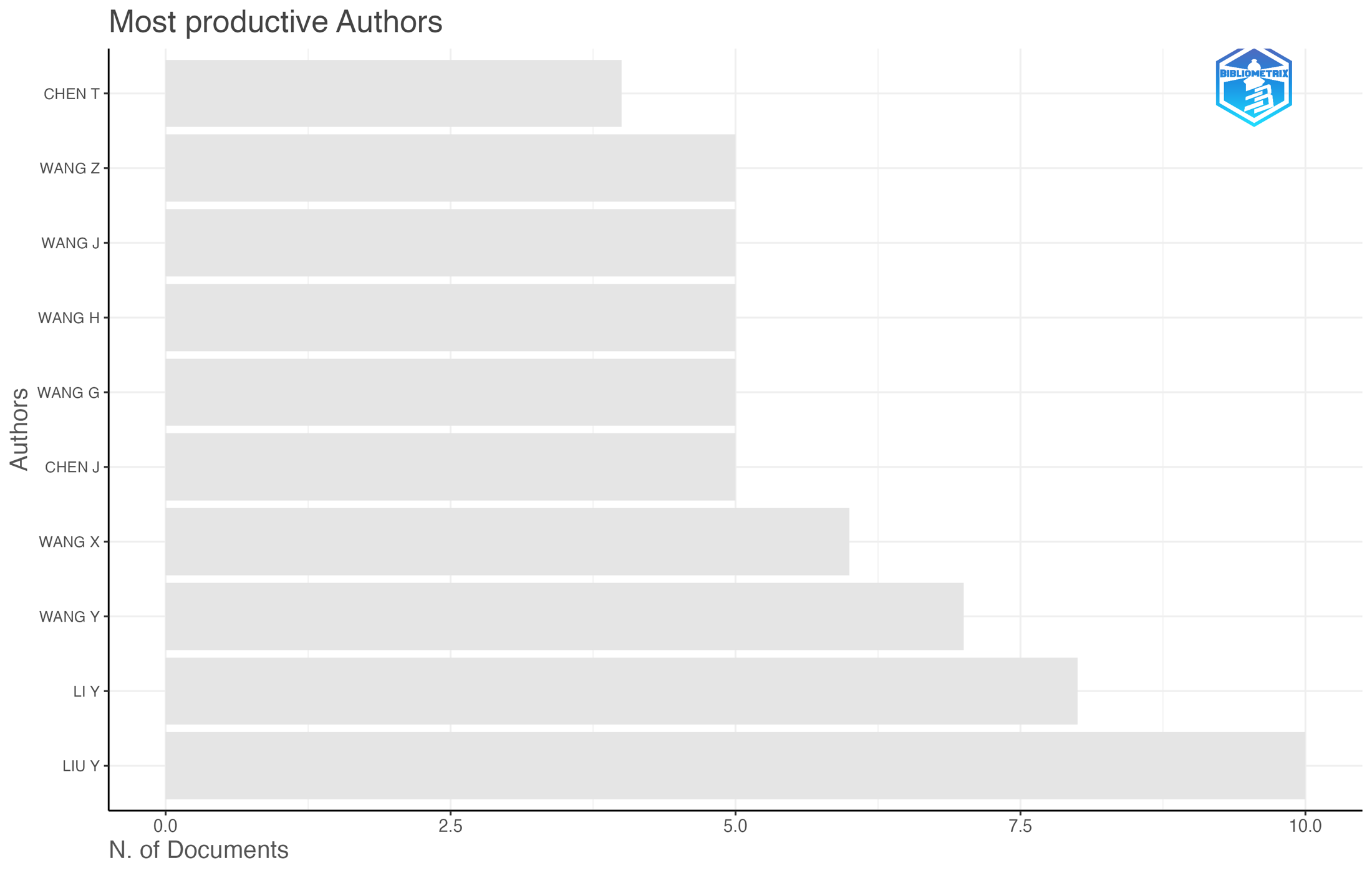
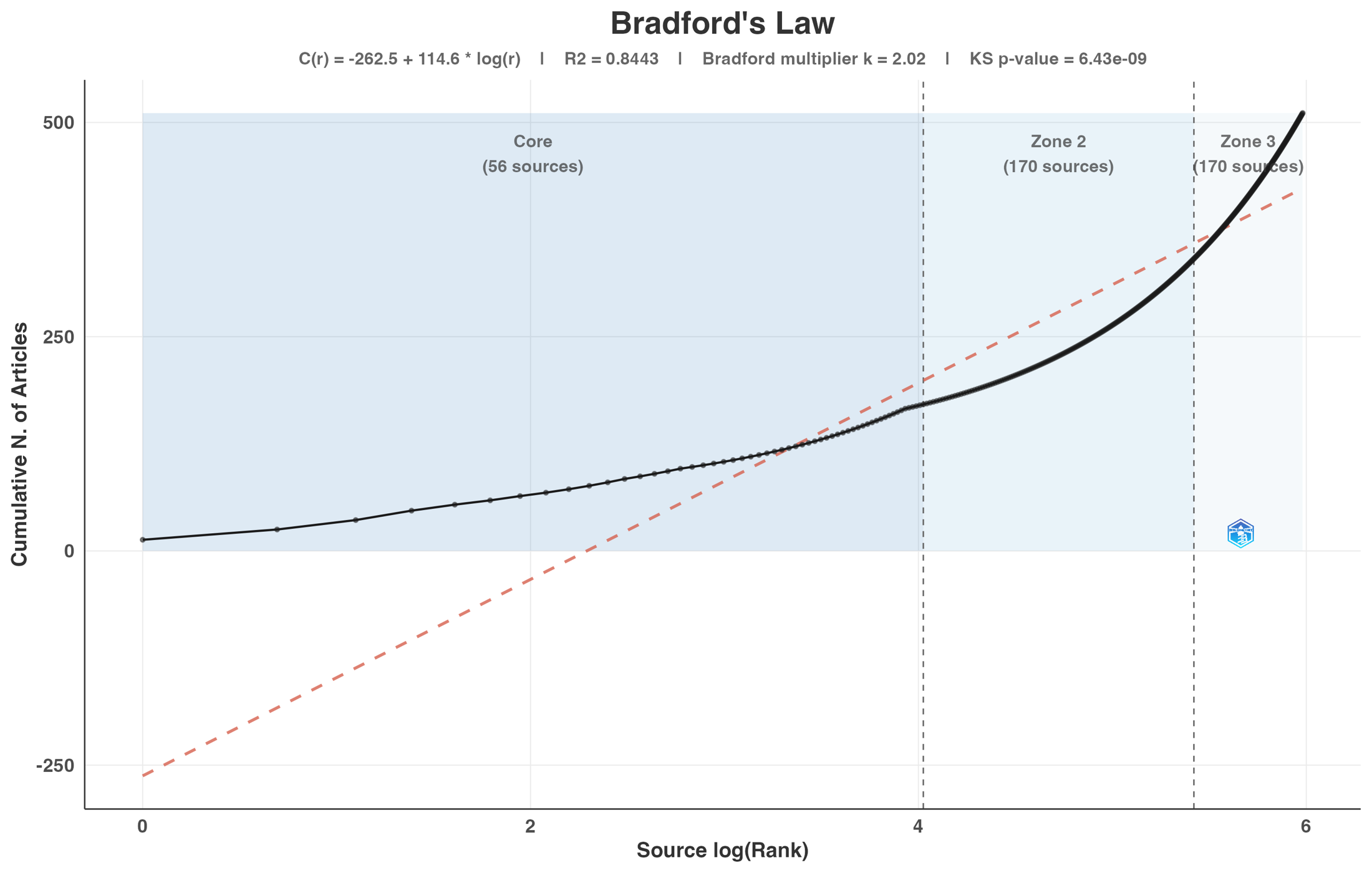
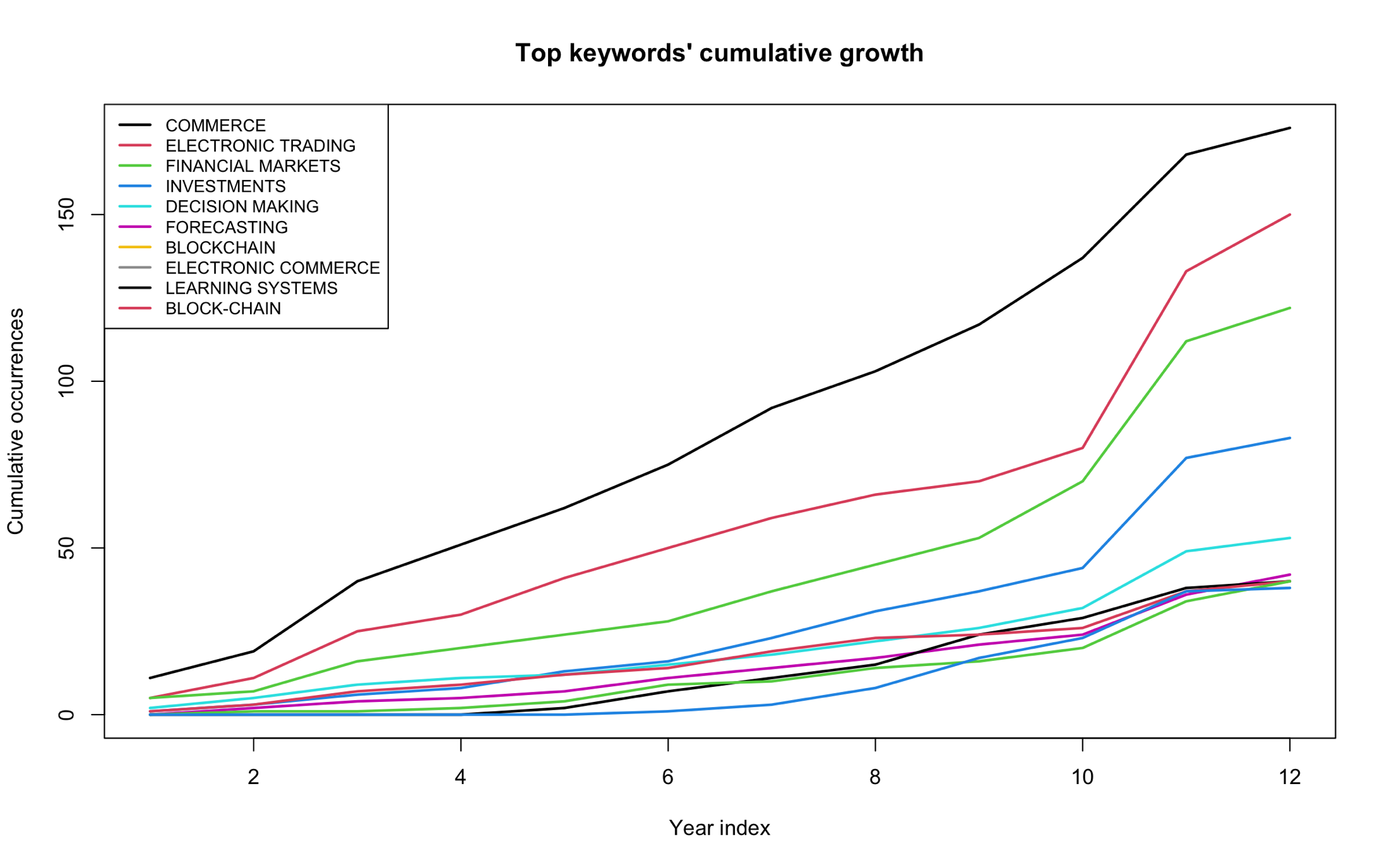
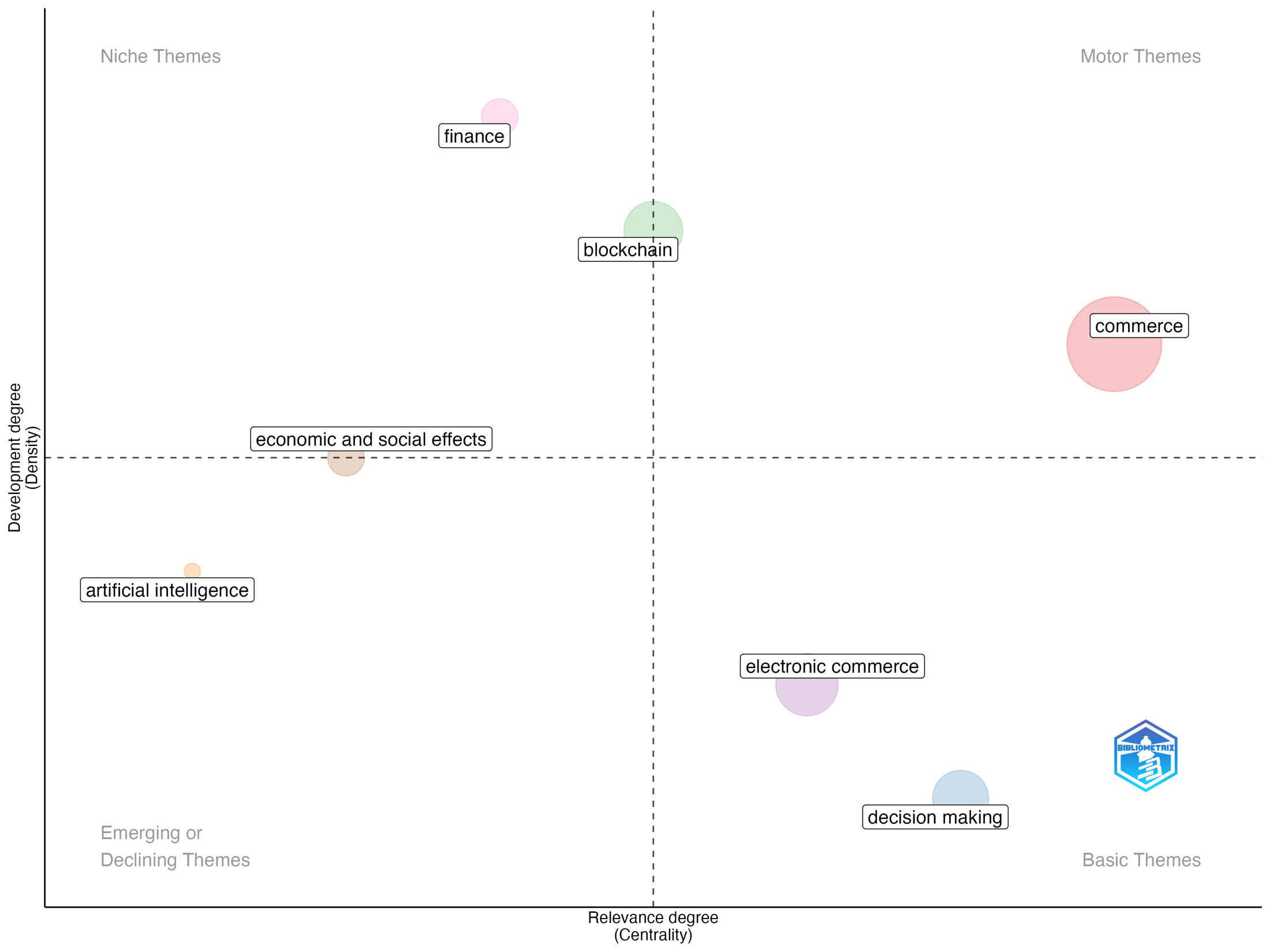
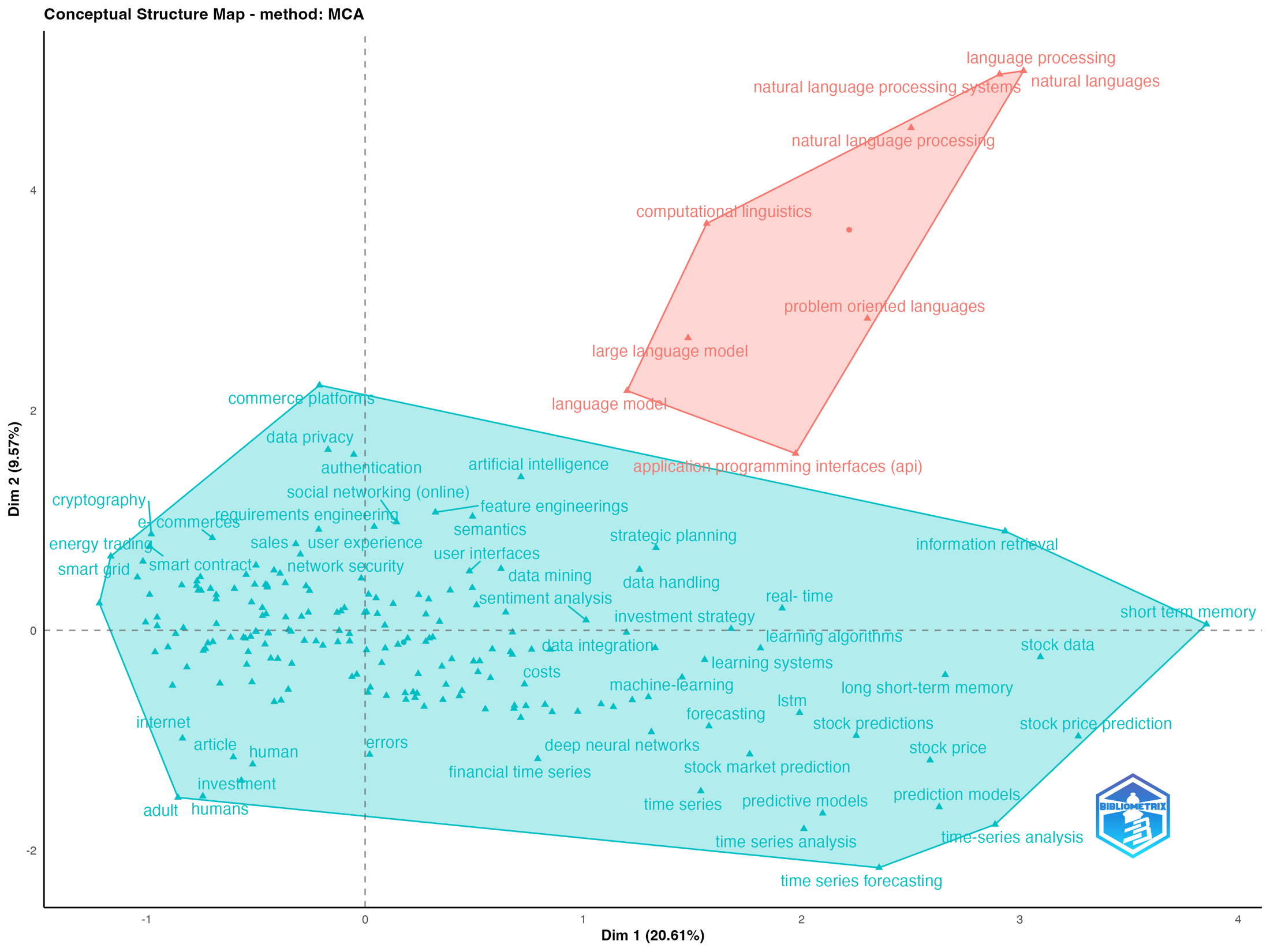
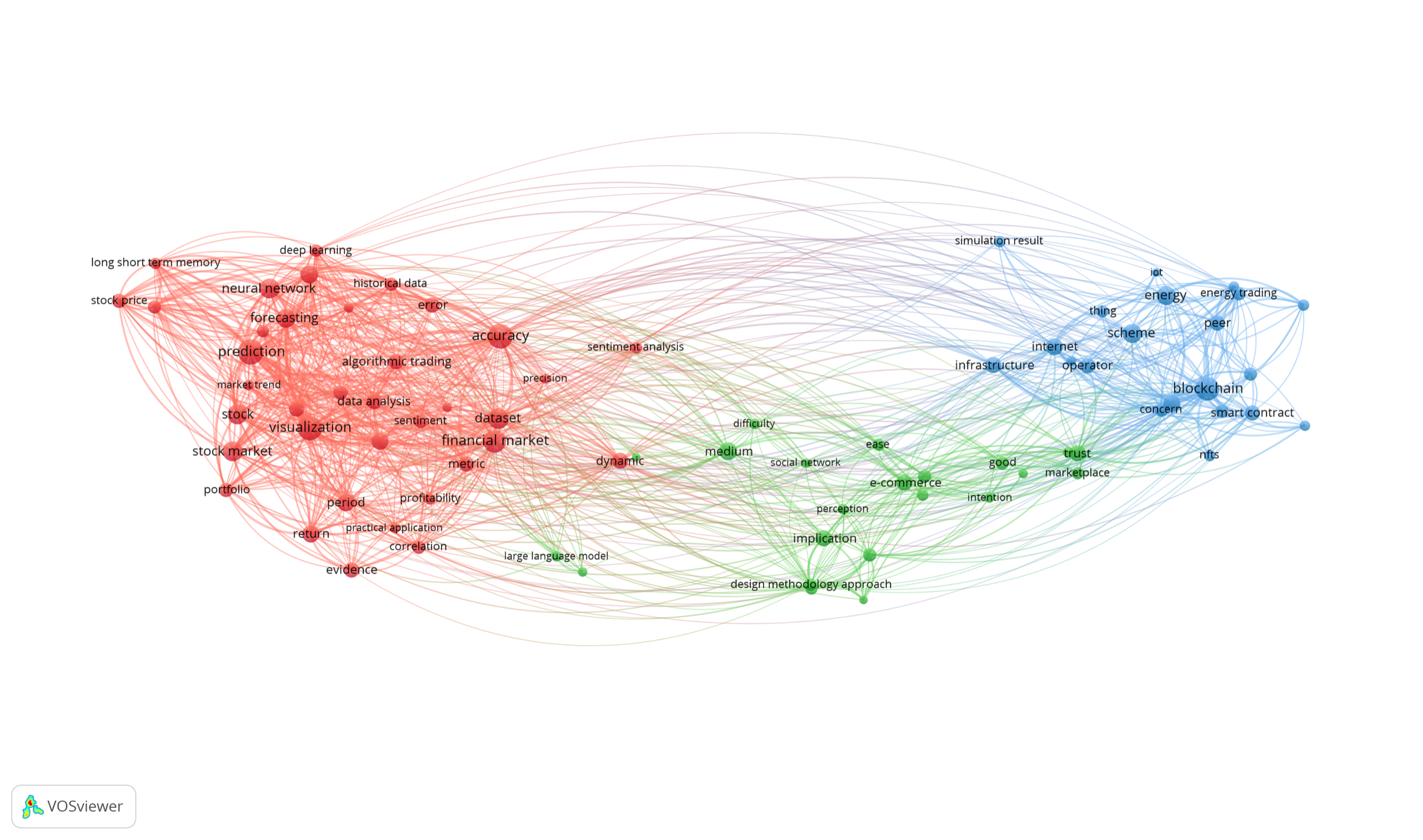
I started by turning the review into a research system
My first decision was methodological: I did not want the project to end as a static spreadsheet. I wanted a workflow where I could load the Scopus exports, tune the term filters, rerun the analysis, inspect each output, and download the evidence. The Shiny dashboard gave me that control surface, so the case study became something I could demonstrate and reproduce rather than only describe.