I modeled ecosystem stress, not just a regression equation
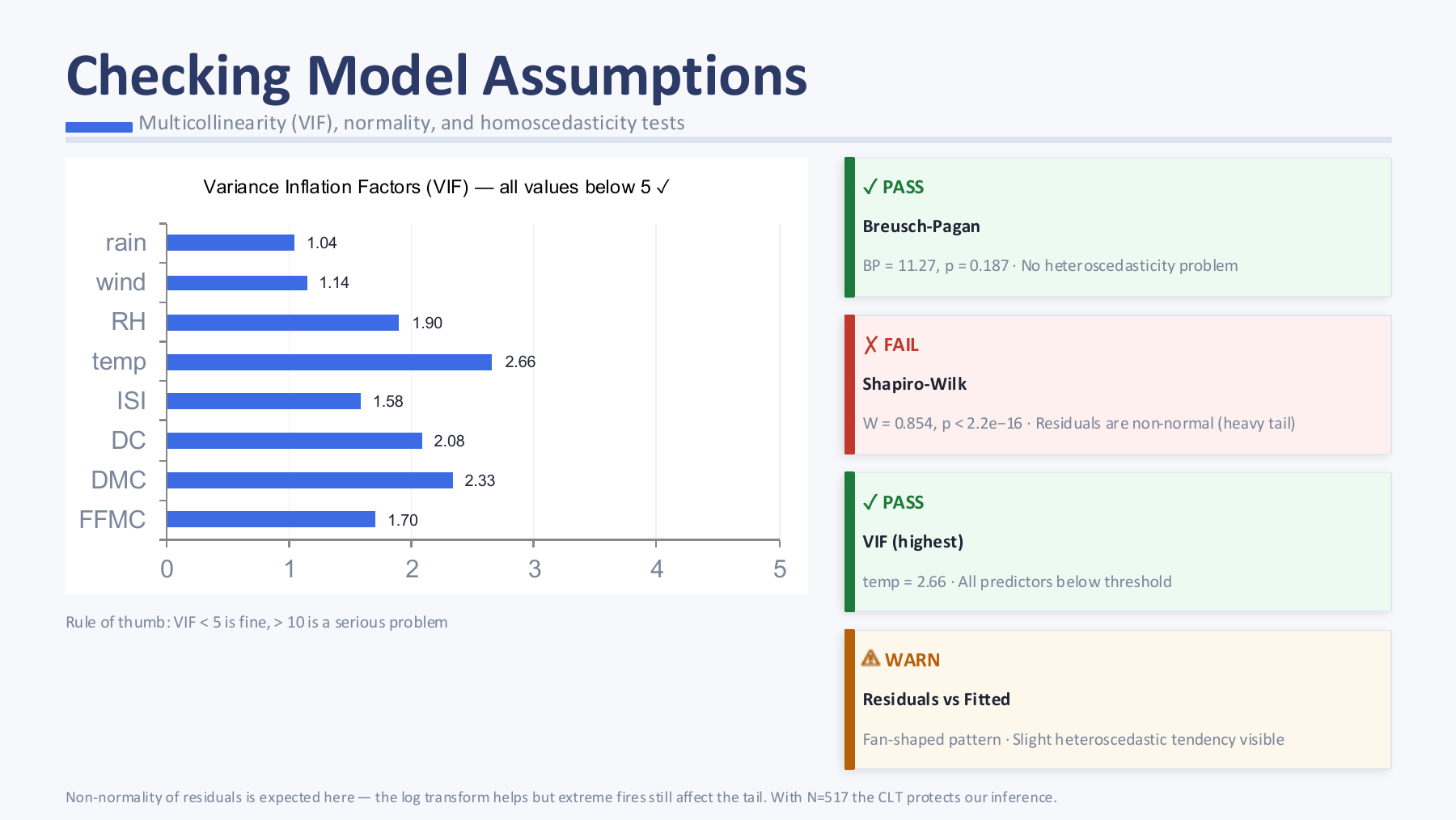
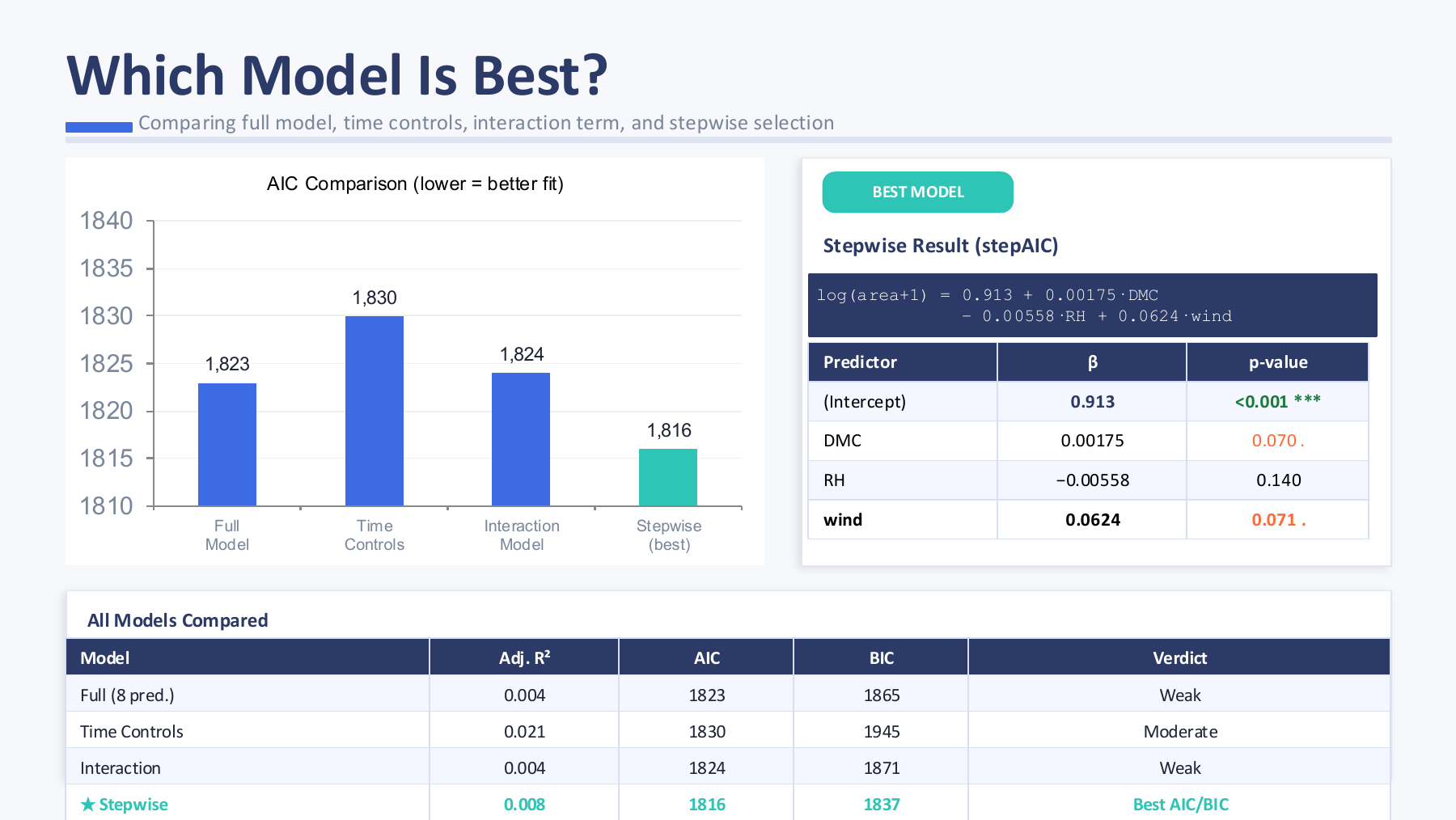
I framed this project around a real analytical tension: forest-fire burned area is not a neat classroom response variable. Most observations are small, a few are extreme, and the process is shaped by weather, fuel moisture, wind, terrain, vegetation, and human response. My job was to use multiple regression carefully without pretending that the available variables could explain the whole ecological system.